在 4 月底上線的「ChatGPT Prompt Engineering for Developers」課程中(可參考之前的筆記),DeepLearning.AI 創辦人吳恩達 Andrew Ng 和 OpenAI 的 Isa Fulford 分享了如何正確且有效的對 ChatGPT 進行 「提示」(prompt)。然而,要開發一個系統會需要由許多 prompts 組成並對大型語言模型(LLM)進行多次調用。 因此,在這次新推出的《Building Systems with the ChatGPT API》的課程中,將會分享如何使用 LLM 來開發複雜的應用程式,並以打造一個全流程的客服輔助系統作為範例來進行講解。

這堂「Building Systems with the ChatGPTAPI」線上課程,在 DeepLearning.AI 網站上免費提供給想要使用 ChatGPT API 的打造系統的開發者學習,瞭解使用 ChatGPT API 打造系統服務時需要注意的細節及實作方式,課程搭配 Jupyter notebook 提供範例程式碼讓學員能即時驗證。
這堂長度為1小時左右的課程內容涵蓋了以下幾個部分:
- 評估輸入:分類(Classification)、審查(Moderation)
- 處理輸入:思想鏈推理(Chain of Thought Reasoning)、提示鏈(Chaining Prompts)
- 檢查輸出
- 打造一個全流程的系統
- 評估成效(Evaluation)
以下為筆者整理的課堂筆記,推薦有興趣的讀者撥出一小時去看完整的課程,肯定會有不少收穫。
大型語言模型、API 格式、Token
在課程開頭,先簡單介紹了監督式學習(Supervised Learning)和大型語言模型(LLM)。
監督式學習
在訓練監督式學習的模型主要有三大步驟:
- 取得標記資料
- 使用這些資料來訓練 AI 模型
- 部署並調用模型
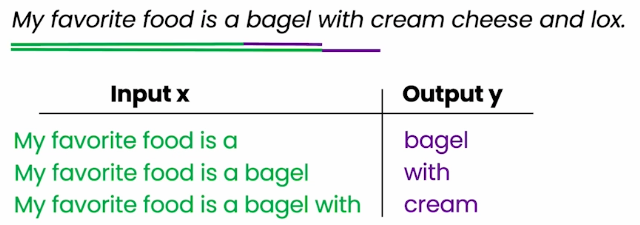
語言模型就是透過監督式學習來反覆預測下一個字詞,如下圖:
而在上一堂課中曾介紹過大型語言模型主要分為兩種:Base LLM 及 Instruction Tuned LLM,可以透過以下步驟來將 Base LLM 轉換成 Instruction Tuned LLM:
- 使用大量資料來訓練 Base LLM
- 持續訓練該模型:
- 使用一些包含輸入指令及輸出結果的範例對模型進行微調(Fine-tune)
- 取得人類對不同 LLM 輸出結果的品質評分,評斷依據包含是否有用、是否誠實、是否無害
- 調整模型以增加產生更高評分的輸出結果的機率(即 RLHF:Reinforcement Learning from Human Feedback)
Token
LLM 實際上做的是反覆預測下一個 token。而什麼是 token?和字詞又有什麼不同?
這邊舉了 3 個例子來說明:
-
範例一
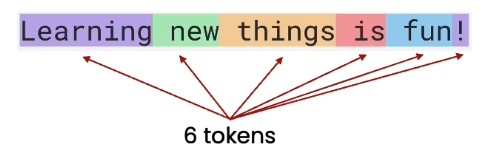 “Learning new things is fun!” 這個句子包含了 6 個 tokens
“Learning new things is fun!” 這個句子包含了 6 個 tokens -
範例二
 “Prompting is a powerful developer tool.” 這個句子中的 “prompting” 並非常見的英文字詞,因此可能會被誤判為 3 個 tokens
“Prompting is a powerful developer tool.” 這個句子中的 “prompting” 並非常見的英文字詞,因此可能會被誤判為 3 個 tokens -
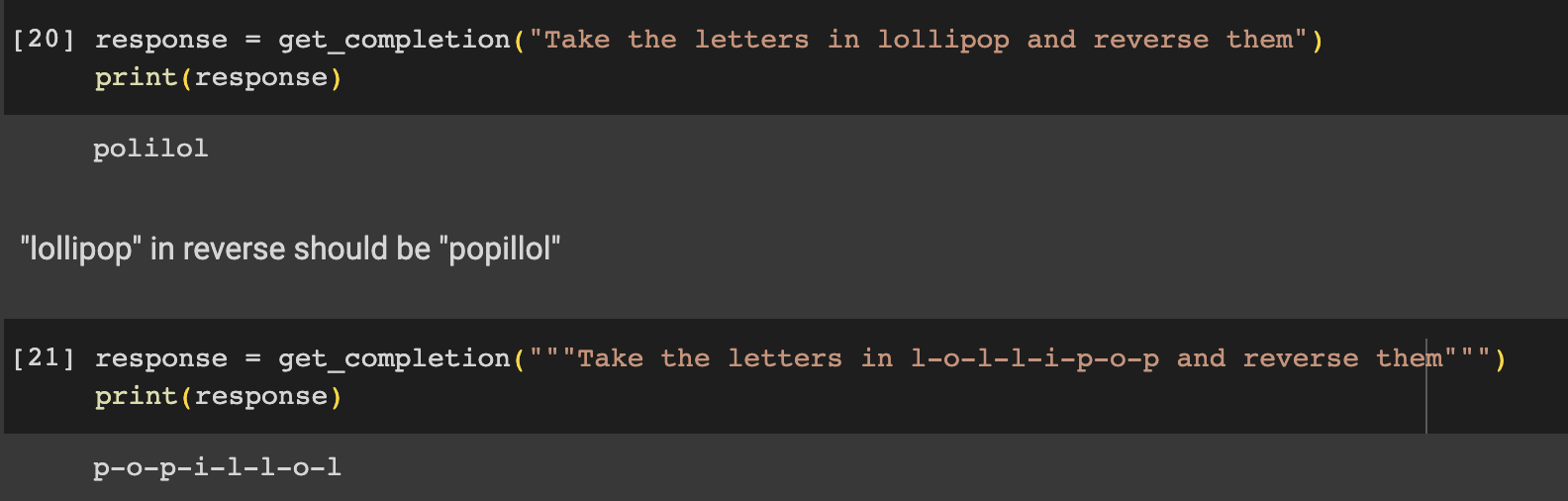
範例三 如果想要讓 ChatGPT 對字詞(如
lollipop)進行順序反轉,若使用的 prompt 為 “Take the letters in lollipop and reverse them”,則會產生錯誤結果,這時可以在字母之間加上破折號(-),即可取得正確的回覆,如下圖。
Prompt 正在改革 AI 應用程式開發
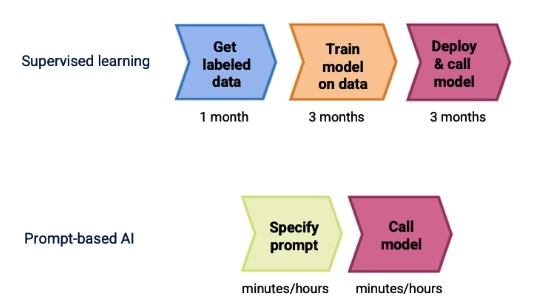
可以從下圖看出使用傳統監督式學習模型和使用以 prompt 為基礎的模型的開發流程差異極大。監督式學習的模型開發從取得資料到最終部署上線可能會耗費半年以上的時間,然而以 prompt 為基礎的模型開發可能只需要幾分鐘到幾小時即可開發出具備 AI 模型的應用程式。
評估輸入
對輸入進行分類:Classification
對於需要大量且獨立的指令來處理不同情況的任務,先對輸入的查詢進行分類,再依據該分類來確認要使用哪些相對應的指令會是很有幫助的。
以課程中家電客服輔助系統為例,可以將使用者的輸入分為 4 個主類別,分別為「帳務費用」、「技術支援」、「帳單管理」及「一般問題」。每個主類別中各自有不同的子類別,例如在「帳號管理」主類別中有「重設密碼」、「更新個人資訊」、「關閉帳號」、「帳號安全」等子類別。
因此,可以指定 system 角色先針對輸入的查詢文字進行分類,並可依據該分類繼續執行相對應的步驟。
對輸入進行審查:Moderation
如果是開發一個可以讓使用者輸入資訊的系統,檢查使用者是否惡意使用或試圖濫用系統是很重要的。這邊介紹了如何使用 OpenAI 的 Moderation API 來對輸入內容進行審查,以及如何使用不同的 prompt 來偵測是否有 提示注入(Prompt Injection)。
可以先透過 Moderation API 去審查使用者的輸入屬於以下幾種負面類別:
| 類別 | 說明 |
|---|---|
| hate | 基於種族、性別、民族、宗教、國籍、性取向、殘疾狀況或種姓表達、煽動或促進仇恨的內容。 |
| hate/threatening | 仇恨內容還包括對目標群體的暴力或嚴重傷害。 |
| self-harm | 提倡、鼓勵或描述自殘行為的內容。 |
| sexual | 意在引起性興奮的內容,例如對性活動的描述,或宣傳性服務的內容。 |
| sexual/minors | 包含 18 歲以下個人的色情內容。 |
| violence | 宣揚或美化暴力或頌揚他人的痛苦或屈辱的內容。 |
| violence/graphic | 以極端的畫面細節描繪死亡、暴力或嚴重身體傷害的暴力內容。 |
Prompt Injection
這邊所指的 Prompt Injection 指的是使用者意圖藉由提供試圖覆蓋掉或是繞過開發者設定的初始指令或限制的輸入,進而操縱 AI 系統,如下圖。
 Prompt Injection 可能會倒導致 AI 系統被非法使用,因此偵測並防止 prompt injection,讓系統是負責任的且有效控制成本是非常重要的。以下介紹兩種主要策略:
Prompt Injection 可能會倒導致 AI 系統被非法使用,因此偵測並防止 prompt injection,讓系統是負責任的且有效控制成本是非常重要的。以下介紹兩種主要策略:
- 在系統訊息中使用分隔符號(如
###,""")和清楚的指令。 - 使用一個額外的 prompt 來偵測使用者是否在試圖使用 Prompt Injection
處理輸入
思想鏈推理(Chain of Thought Reasoning)
有時模型在回答特定問題之前,需要先針對問題進行詳細推理(reasoning),來避免因為問題推理錯誤而產生錯誤的回覆。而這個讓模型按照步驟行推理的策略稱為 「思想鏈推理」(Chain of Thought Reasoning)。
然而,在某些應用中,模型在產出最終答案的過程中所使用的推理過程,可能不適合讓使用者知道。這時候就可以使用 「內心獨白」(Inner Monologue) 的方法,即對使用者隱藏模型的推理過程。實際作法是將模型輸出的某些部分調整成結構化格式,以便將這些內容隱藏起來,只將需要讓使用者知道的資訊回覆給使用者。
提示鏈(Chaining Prompts)
提示鏈(Chaining Prompts)是指將多個 prompts 鏈接在一起,將複雜任務拆解成一系列更簡單的子任務。
思想鏈推理和提示鏈的比喻就像是一次性做好一整桌菜和分階段做好一桌菜。使用一個又長又複雜的指令就像一次性做好一整桌菜,必須同時處理很多食材並且擁有一手好廚藝;而提示鏈就像是分階段做完一桌菜,可以專心一次處理一道菜,確保每道菜都在下一道菜之前煮好,透過將各種中間的狀態保存下來,並依據當前狀態決定後續操作。
提示鏈有以下優點:
- 更專注:將任務的複雜度拆解,使其更易於管理,降低出錯的機率拆解
- 降低成本:prompt 愈長,token 就愈多,成本就愈高
- 可以忽略某些不必要的步驟
- 更容易測試,甚至在特定步驟中讓人工介入
- 能記錄複雜任務的狀態,並讓 LLM 外的其他程式能獲得此資訊
檢查輸出
在向使用者顯示之前必須先檢查輸出結果,以確保提供給使用者或自動化流程中的內容的品質、相關性和安全性。這邊將會介紹如何使用 OpenAI Moderation API 來審查輸出內容,以及如何在顯示給使用者之前透過額外的 prompt 讓模型評估輸出的品質。
使用 Moderation API 來檢查輸入的方法和前幾章節中 對輸入進行審查:Moderation 中介紹的方法一樣,也可以將模型輸出的內容搭配適當的 prompt 提交給模型來評估輸出的品質。
一般而言,使用 Moderation API 來檢查輸出是個好習慣。但講者認為,雖然讓模型評估自己的輸出對於即時回饋可能有用,以確保在極少數情況下回傳高品質的結果,但大多數時候可能不是必要的,特別是使用了更先進的模型(如 GPT-4),因為這會增加系統延遲並提高成本。
打造一個全流程的系統
透過上述所分享的步驟來開發一個完整的客服輔助系統。
- 首先,使用內容審核 API 檢查輸入內容,確認是否被標記有問題
- 若無,則取得產品列表
- 試著查找產品列表
- 用模型來回答使用者的問題
- 將答案透過內容審審核 API 檢查
- 若沒有被標記有問題,則將答案回傳給使用者
評估成效(Evaluation)
在依照上述教學和步驟開發出一個 AI 系統後,要如何評量其運作情形?而當系統正式上線後,要如何追蹤其成效?發現成效不夠好時,要如何持續提升系統回覆答案的品質?在這章節中,將會分享評估 LLM 輸出的最佳做法。
和傳統訓練監督式學習模型相比,在開發 prompt-based 的 AI 模型時,通常會有以下幾種感受:
- 在少量的例子上調整 prompt
- 慢慢將一些棘手的特殊例子加到正在測試的資料集中
- 制定指標去衡量這些例子的成效,如 average accuracy
- 收集隨機抽樣的資料集來調整模型(開發測試資料集或保留交叉驗證資料集)
- 收集並使用保留測試資料集
Andrew Ng 表示對於很多應用而言,只要做到上述前三點就足夠了,但如果正在開發對於安全性要求很高的應用或有潛在實質性傷害風險的應用,那麼負責任的做法當然是在被任何人使用之前,都必須進行大規模的資料集驗證以嚴格的驗證其準確性。
課程總結
在這堂一小時的課程中,主要介紹了以下幾個重點:
- LLM、Token 及 角色
- 評估 使用者 輸入 的方法,以確保系統的品質和安全
- 使用 思維鏈推理 和 提示鏈 將任務拆分成子任務來 處理輸入
- 在將結果顯示給使用者之前 檢查輸出
- 在不同時間點評估系統的方法,以監控和提升其效能 這堂課的內容對於有志串接 ChatGPT API 來打造 AI 服務的開發者而言,是非常推薦的學習資源,這篇筆記內容有限,歡迎有興趣了解更多的讀者前往觀看課程及閱讀官方文件。
《DTW 數位科技週報》
如果想要每週獲得最新的數位科技、區塊鏈及人工智慧新聞整理,歡迎訂閱免費電子報:《DTW 數位科技週報》